Everything works based on data. In the enterprise, this data needs to be stored into powerful, scalable and robust data platforms (Relational Database Management Systems – RDBMSs) which allow the future processing and transformation of data into knowledge.
Transforming data into knowledge, in many cases, is not an easy task. It can involve complex queries, nested loops, aggregations, etc. thus requiring large design efforts and considerable amounts of execution time.
We many times find ourselves in the process of thinking of a complex query, struggling to satisfy a complex business requirement, always trying to find a way to “instruct” our data platform how to extract the required data/knowledge. Such processes can take hours, if not days.
In such cases, our way of thinking is directly focused on the end result thus trying to “capture” the solution in its whole. This is a process-driven approach towards the transformation of large amounts of raw data into knowledge.
The more complex the business requirement is the more complex and time-consuming this process-driven approach will be. It might sometimes end up to dead ends as well.
There are many times where I need to solve a quite complex business requirement when it comes to the transformation of data stored into SQL Server into knowledge.
It is then when the following thoughts pass through my mind:
abstraction…
principles…
data sets…
solve smaller issues…decomposition…
combine them…
solve the problem
The above thoughts are not random. They are actually based on well-established principles of Computer Science that are widely used in software development.
Abstraction is the process by which when you have a complex problem to solve in programming, you do not focus on the implementation details. You instead focus on the semantics and you build different abstraction layers.
Decomposition is the process by which you break a complex problem into smaller parts, you then deal with each one of those parts and in the end you combine them in order to form the solution to the original problem.
The question is why not applying Abstraction and Decomposition in the Data World or at least using them more? I am not saying to follow a strict data-driven programming paradigm rather than a method which takes into consideration the available data too and how it is organized in the DBMS. The suggested approach is described in the following diagram:
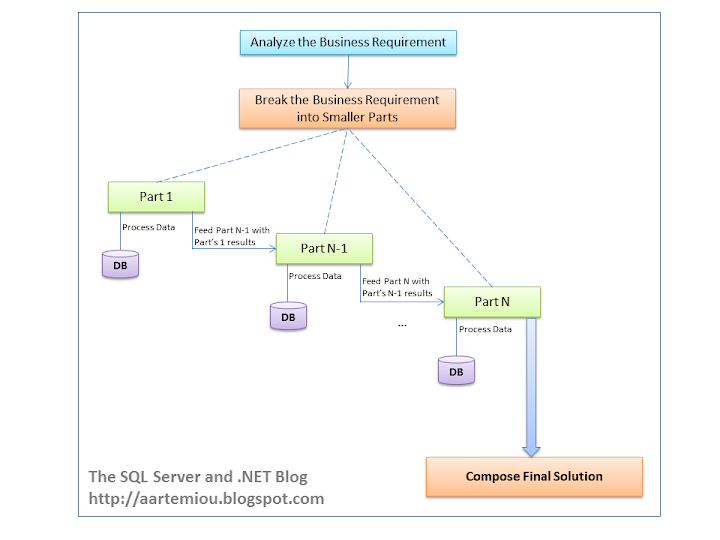 |
| Diagram 1: Suggested Workflow for Transforming Data Into Complex Knowledge |
As illustrated in the above diagram, the suggested workflow features the following steps:
- Receive and analyze the business requirement (use abstraction).
- Break the business requirement into smaller parts (use decomposition).
- For each part:
- Write the SQL code
- Execute it
- Feed the data to the next part (you may use data import/export, integration services, etc.)
- After the execution of all parts is completed you end up to the final data set that contains the result to the business requirement.
I am quite sure that in many cases we use the above approach without really identifying it or giving it a label.
However, when you are given a complex business requirement, especially in enterprise environments, you cannot just start writing code! I know, I like it too 🙂 but you need to have a plan or else you might end up coding, testing, and re-coding SQL code all over without easily producing the final result!
So whenever you have a complex data challenge to face, you can break it into parts and work on each part cumulatively by developing it, executing it and feeding its results to the next part. This is the road to extracting complex knowledge out of your DBMS, this is the road to mastering the Data World!
Artemakis Artemiou, a distinguished Senior Database and Software Architect, brings over 20 years of expertise to the IT industry. A Certified Database, Cloud, and AI professional, he earned the Microsoft Data Platform MVP title for nine consecutive years (2009-2018). As the founder of SQLNetHub and GnoelixiAI Hub, Artemakis is dedicated to sharing his knowledge and democratizing education on various fields such as: Databases, Cloud, AI, and Software Development. His commitment to simplicity and knowledge sharing defines his impactful presence in the tech community.