
In this article, we will be discussing about using Unicode in SQL Server.
Introduction
Unicode is the standard used in the computing industry for encoding and representing any text in the most written languages (…).
SQL Server supports Unicode, thus allowing the easy storage and manipulation of data in the most languages.
Example Using Unicode
As I wanted to test this functionality I performed a simple experiment with the Cyrillic alphabet.
To this end I created two tables in SQL Server, the one in non-Unicode and the other one in Unicode:
CREATE TABLE tStandard( [name] varchar(100) ); GO CREATE TABLE tUnicode( [name] nvarchar(100) ); GO
As you can see, in the tStandard table the “name” field’s data type is varchar and in the tUnicode table the “name” field’s data type is nvarchar.
The difference between the varchar and nvarchar data types is that the former uses 1 byte for representing characters where the later uses 2 bytes thus supporting Unicode.
Then I created a text file in Unicode containing three records with my name in Russian:
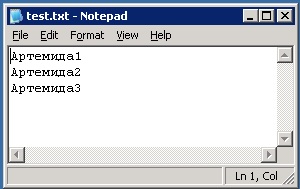
The next step was to import the data into the two tables using the SQL Server Import and Export Wizard. As you can see from the screenshot below, when I tried to import the data into the tStandard table the process failed because of the fact that the data did not match the target code page (GREEK_CI_AS):

But what about if we want to represent any language without relying on the target database’s code page/collation?
The answer is easy; Use nvarchar(s)!
Let’s see what happened with the rest of my experiment.
Here’s the result of trying to import the data into the tUnicode table:

Yep, the data was imported successfully!
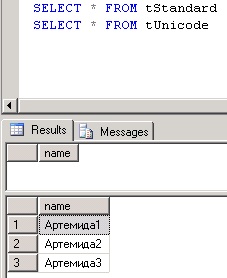
And here’s the SELECT * query’s results when executed against the two tables:
Concluding Remarks
The conclusion out of this experiment is that by using nvarchar, SQL Server can easily support the storage and representation of data in most written languages.
The only thing you need to have in mind, is that when using Unicode data types such as the nvarchar, the required storage will be doubled in comparison with using non-Unicode data types (i.e. varchar).
Learn more useful SQL Server development tips!
Enroll to our Online Course!Check our online course titled “Essential SQL Server Development Tips for SQL Developers” (special limited-time discount included in link).
Sharpen your SQL Server database programming skills via a large set of tips on T-SQL and database development techniques. The course, among other, features over than 30 live demonstrations!

Featured Online Courses:
- Boost SQL Server Database Performance with In-Memory OLTP
- Essential SQL Server Administration Tips
- SQL Server Fundamentals – SQL Database for Beginners
- Essential SQL Server Development Tips for SQL Developers
- The Philosophy and Fundamentals of Computer Programming
- .NET Programming for Beginners – Windows Forms with C#
- Introduction to SQL Server Machine Learning Services
- Introduction to Azure SQL Database for Beginners
- SQL Server 2019: What’s New – New and Enhanced Features
- Entity Framework: Getting Started – Complete Beginners Guide
- How to Import and Export Data in SQL Server Databases
- Learn How to Install and Start Using SQL Server in 30 Mins
- A Guide on How to Start and Monetize a Successful Blog
Read Also:
- Essential SQL Server Development Tips for SQL Developers
- The TempDB System Database in SQL Server
- SQL Server Installation and Setup Best Practices
- The feature you are trying to use is on a network resource that is unavailable
- SQL Server 2016: TempDB Enhancements
- tempdb growth
- Introduction to SQL Server Machine Learning Services
- Essential SQL Server Administration Tips
- What are SQL Server Statistics and Where are they Stored?
- …more
Check our other related SQL Server Development articles.
Subscribe to our newsletter and stay up to date!
Check out our latest software releases!
Check out our eBooks!
Rate this article:  (2 votes, average: 5.00 out of 5)
(2 votes, average: 5.00 out of 5)![]() Loading...
Loading...
Reference: SQLNetHub.com (https://www.sqlnethub.com)
© SQLNetHub
Artemakis Artemiou is a seasoned Senior Database and AI/Automation Architect with over 20 years of expertise in the IT industry. As a Certified Database, Cloud, and AI professional, he has been recognized as a thought leader, earning the prestigious Microsoft Data Platform MVP title for nine consecutive years (2009-2018). Driven by a passion for simplifying complex topics, Artemakis shares his expertise through articles, online courses, and speaking engagements. He empowers professionals around the globe to excel in Databases, Cloud, AI, Automation, and Software Development. Committed to innovation and education, Artemakis strives to make technology accessible and impactful for everyone.